Spark学习笔记之SparkSQL
SparkSQL
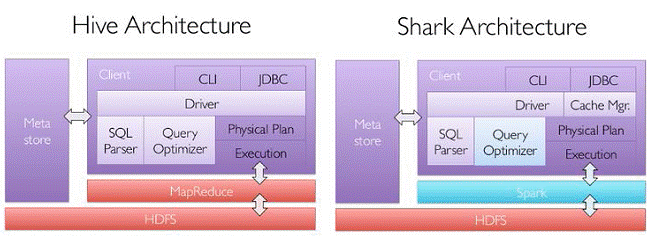
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
MapR的Drill
Cloudera的Impala
Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result–>Data Source–>Operation的次序来描述的。
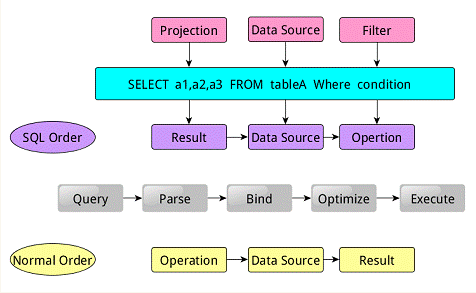
当执行SparkSQL语句的顺序为:
- 对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
- 将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
- 一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
- 计划执行(Execute),按Operation–>Data Source–>Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
Tree和Rule
SparkSQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。
- Tree
- Tree的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees
- Logical Plans、Expressions、Physical Operators都可以使用Tree表示
- Tree的具体操作是通过TreeNode来实现的
- SparkSQL定义了catalyst.trees的日志,通过这个日志可以形象的表示出树的结构
- TreeNode可以使用scala的集合操作方法(如foreach, map, flatMap, collect等)进行操作
- 有了TreeNode,通过Tree中各个TreeNode之间的关系,可以对Tree进行遍历操作,如使用transformDown、transformUp将Rule应用到给定的树段,然后用结果替代旧的树段;也可以使用transformChildrenDown、transformChildrenUp对一个给定的节点进行操作,通过迭代将Rule应用到该节点以及子节点。
TreeNode可以细分成三种类型的Node:
- UnaryNode 一元节点,即只有一个子节点。如Limit、Filter操作
- BinaryNode 二元节点,即有左右子节点的二叉节点。如Jion、Union操作
- LeafNode 叶子节点,没有子节点的节点。主要用户命令类操作,如SetCommand
Rule
Rule的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules
- Rule在SparkSQL的Analyzer、Optimizer、SparkPlan等各个组件中都有应用到
- Rule是一个抽象类,具体的Rule实现是通过RuleExecutor完成
- Rule通过定义batch和batchs,可以简便的、模块化地对Tree进行transform操作
- Rule通过定义Once和FixedPoint,可以对Tree进行一次操作或多次操作(如对某些Tree进行多次迭代操作的时候,达到FixedPoint次数迭代或达到前后两次的树结构没变化才停止操作,具体参看RuleExecutor.apply)
sqlContext和hiveContext的运行过程
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器(SQL-92语法);hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法,
sqlContext的运行过程
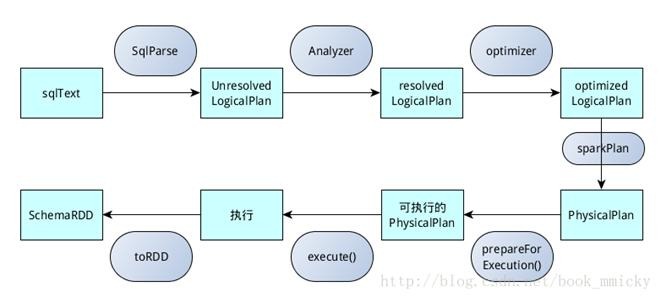
sqlContext总的一个过程如下图所示:
- SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
- 使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
- 使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
- 使用SparkPlan将LogicalPlan转换成PhysicalPlan;
- 使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
- 使用execute()执行可执行物理计划;
- 生成SchemaRDD。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等
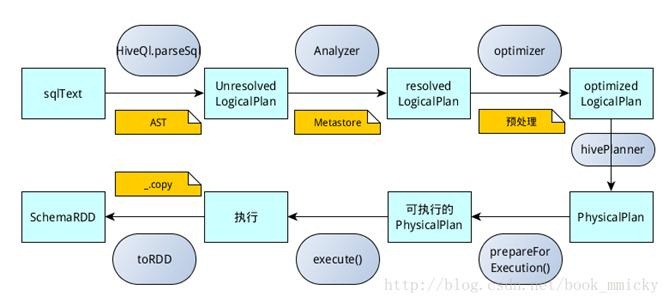
- hiveContext的运行过程
hiveContext总的一个过程如下图所示:
- SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析;
- 使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
- 使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
- 使用hivePlanner将LogicalPlan转换成PhysicalPlan;
- 使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
- 使用execute()执行可执行物理计划;
- 执行后,使用map(_.copy)将结果导入SchemaRDD。
- catalyst优化器
SparkSQL1.1总体上由四个模块组成:core、catalyst、hive、hive-Thriftserver:
- core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
- catalyst处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
- hive对hive数据的处理
- hive-ThriftServer提供CLI和JDBC/ODBC接口
在这四个模块中,catalyst处于最核心的部分,其性能优劣将影响整体的性能。由于发展时间尚短,还有很多不足的地方,但其插件式的设计,为未来的发展留下了很大的空间。下面是catalyst的一个设计图:
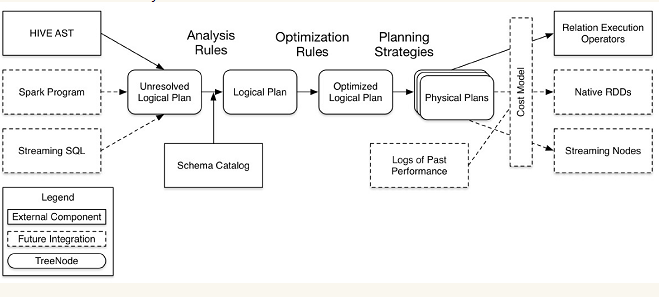
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
- sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
- Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和数据元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
- optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan;
- Planner将LogicalPlan转换成PhysicalPlan;
- CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划
这些组件的基本实现方法:
先将sql语句通过解析生成Tree,然后在不同阶段使用不同的Rule应用到Tree上,通过转换完成各个组件的功能。
Analyzer使用Analysis Rules,配合数据元数据(如hive metastore、Schema catalog),完善Unresolved LogicalPlan的属性而转换成resolved LogicalPlan;
optimizer使用Optimization Rules,对resolved LogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan;
lanner使用Planning Strategies,对optimized LogicalPlan
SparkSQL CLI
CLI(Command-Line Interface,命令行界面)是指可在用户提示符下键入可执行指令的界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后予以执行。Spark CLI指的是使用命令界面直接输入SQL命令,然后发送到Spark集群进行执行,在界面中显示运行过程和最终的结果。
Spark1.1相较于Spark1.0最大的差别就在于Spark1.1增加了Spark SQL CLI和ThriftServer,使得Hive用户还有用惯了命令行的RDBMS数据库管理员较容易地上手,真正意义上进入了SQL时代。